A lightweight Transformer-based visual question answering network with Weight-Sharing Hybrid Attention
Abstract
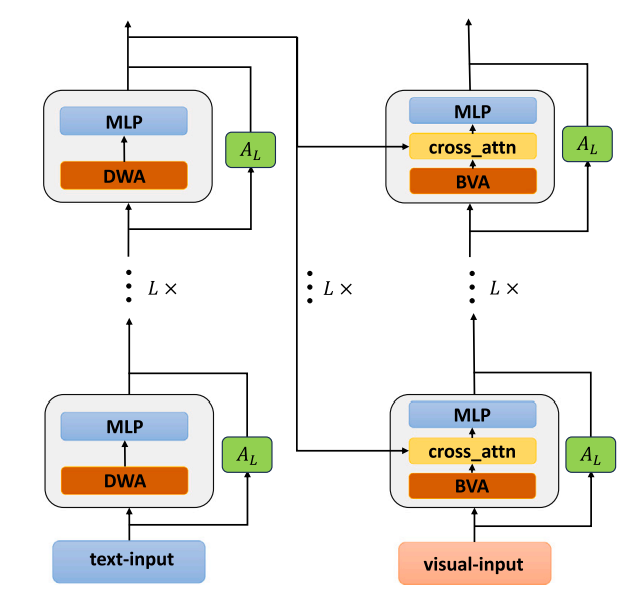
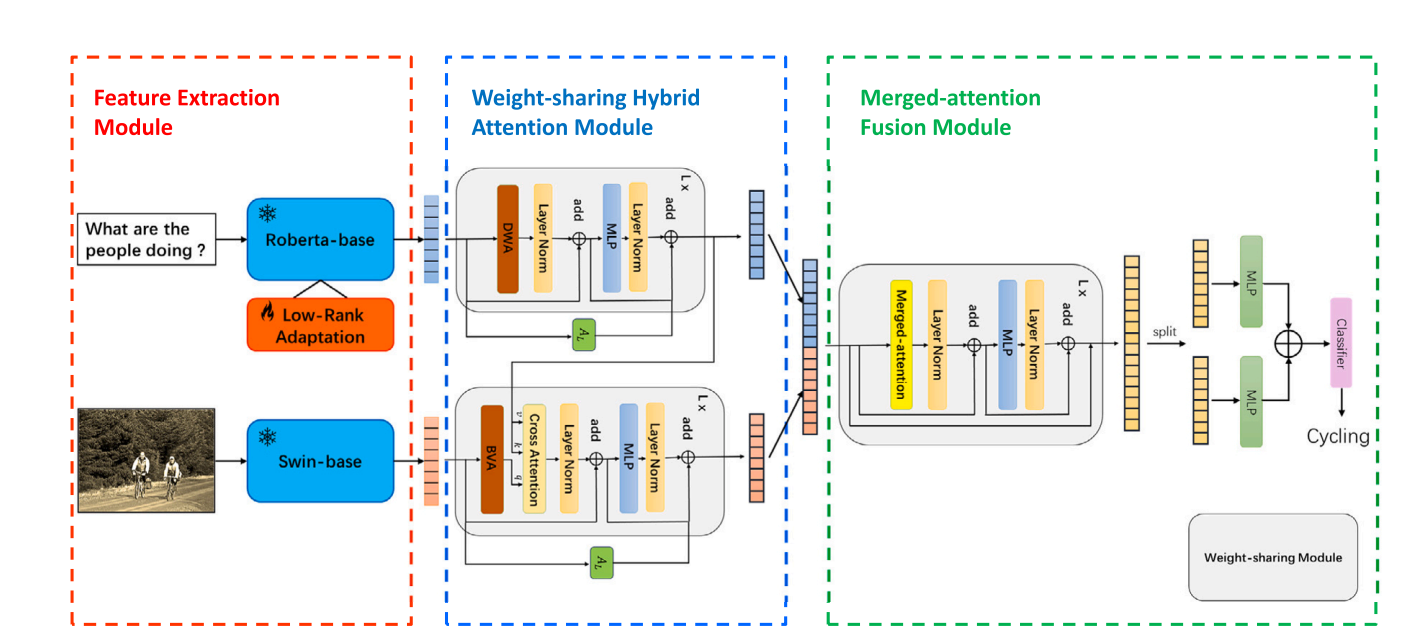
最近的进展表明,基于 Transformer 的模型和基于对象检测的模型在 VQA 中起着不可或缺的作用。然而,基于对象检测的模型由于其冗余和复杂的检测框生成过程而具有很大的局限性。相比之下,视觉和语言预训练 (VLP) 模型可以获得更好的性能,但需要很高的计算能力。为此,我们提出了一种基于 Transformer 的轻量级 VQA 模型——权值共享混合注意网络 (WHAN)。在 WHAN 中,我们用 Transformer 编码器替换对象检测网络,并使用 LoRA 解决语言模型无法适应疑问句的问题。我们提出了具有并行残差适配器的权值共享混合注意 (WHA) 模块,这可以显着减少模型的可训练参数,并且我们设计了 DWA 和 BVA 模块,可以让模型从不同尺度执行注意操作。在 VQA-v2、COCO-QA、GQA 和 CLEVR 数据集上的实验表明,WHAN 以更少的可训练参数实现了具有竞争力的性能
Method